Data Driven Documentation
The world is a loud place, filled with a lot of garbage. In the battle for quality vs. quantity, quality seems to have lost and that is unfortunate. Not that the “publish or perish” paradigm we have constructed doesn’t have some positives, or that the speed of iteration foisted by Silicon Valley hasn’t improved the general condition of humanity (Computers are useful and time saving), but in general it would be phenomenal if we could move that needle back towards quality a bit. I find this to have been a losing battle for a number of reasons.
- A large portion of the time I am the blocker. I am unfixable and have the development velocity of a coconut laden swallow1.
- I sometimes have trouble being outwardly productive because I have no real opinion (or my opinion is just that, an opinion). “Yeah, you could do it that way. There might be more seamless or efficient ways to do that, but if you can accomplish what it is you want to accomplish, I can only assume you’ve moved on to the next pain point and there’s no real reason for me to interject there.”
- I also on more than a few occasions have no idea what audience or level to talk to, and frequently hang out with people who are far too smart for me to be allowed to interact with.
- I’d guess that roughly half of what I call my domain of expertise is the technological, and the digital revolution we continue to undergo not only makes my previous learnings “outdated”, they make them flat out incorrect. Furthermore, even if that “incorrect” were still useful (and it usually is not), the changing computational environments, and increasingly laws/society, grossly degrade the replicability of that knowledge. “Building the airplane as we fly it”, “do it live”, and “fail fast” are not firm foundations on which to construct quality, contribute meaningfully to, or operationalize on.
- I also cannot over emphasize how much I hate both computers and writing.
- I’m not a fan of “learning out loud” either, no one wants to see me flounder like a perch out of water, or watch as I flail like I’m trying to dig a trench with that fish2.
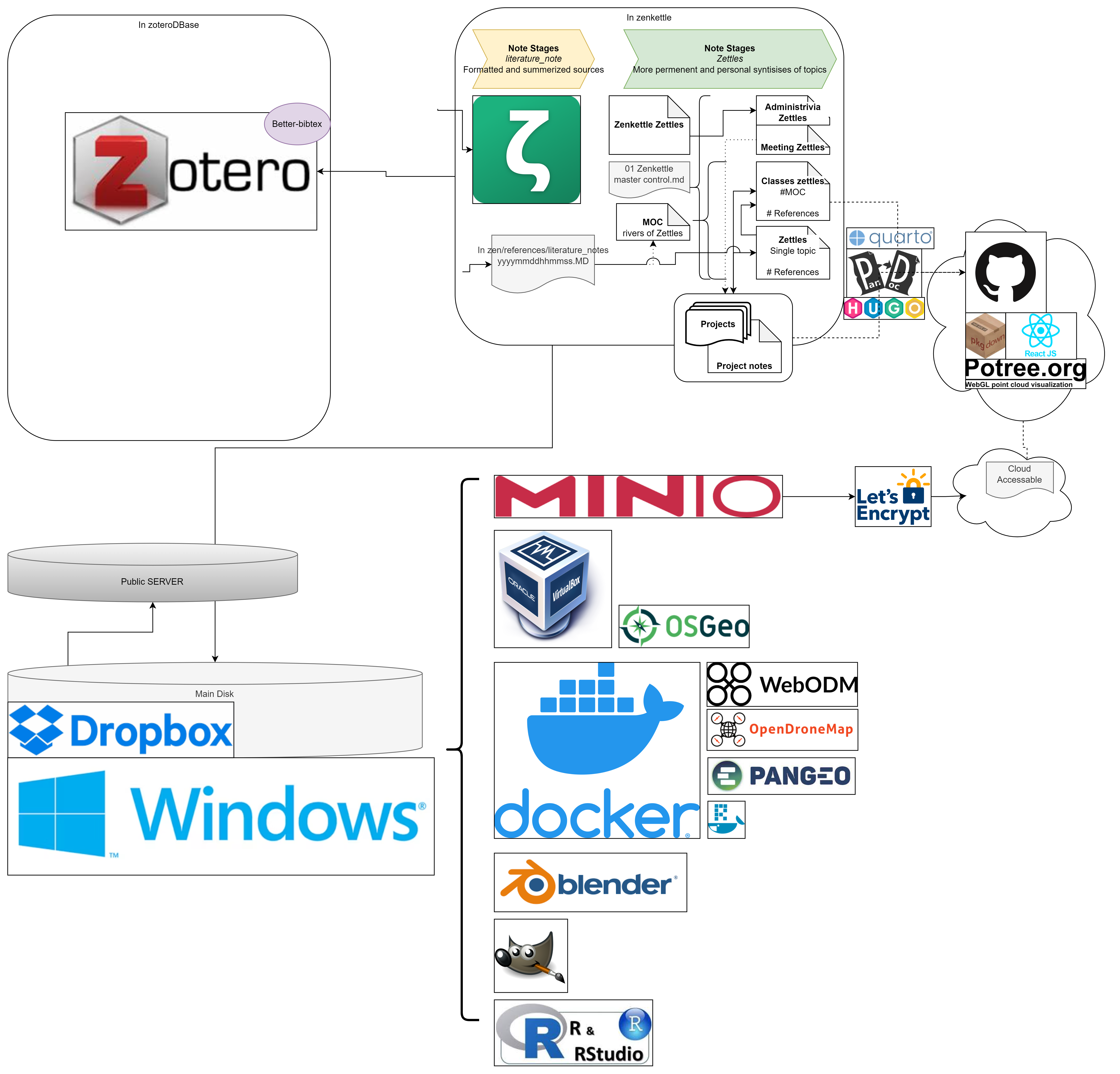
Having spent the time struggling and soul searching, I’ve assembled the monstrosity of a working system you’ve found here. Blending zettlekasten concepts, a Diataxis-styled documentation style, the self-sold confidence of a modified PARA method, and my years of experience creating file bloat to generate this; the newest iteration of my digital footprint. Hopefully working within this framing will reduce the friction I experience with some of those pain points, and provide me with a landscape against which I can have some sort of opinion. Ideally re-framing these opinions into useful output is equally as seamless. Having that knowledge in a synthesized and authoritative form should also allow me to more responsively provide answers and meaningful assistance. If not, at the very least my notes look fancy and I have a consistent starting point to begin [[20230908085243]] The hellscape that is my day :)
Executable writing
There’s a lot of dark corners in the maze between head work and hand work, and the best way I’ve found of truly overcoming that (as opposed to stopgap band-aids and unreplicable solutions), is to make the entire process data driven and executable. In short this means:
- The friction from source to citation is non-existent: Zotero and Zettlr accomplish most of this very nicely/seamlessly as outlined in Note taking.
- There’s a place for virtually every word I need to write. This means that any thought temporarily thrown into [[20220630144912]] 02 Now will eventually have to percolate through the rest of my system.
- Computational reproducibility is a function of the amount of abstraction I’m willing to do, but is generally very high. See:
- How I install GIS.
- How I install and use docker.
- Communicating those results is also highly reproducible since this site is based on Quarto, and so is a data driven, fully contained static site which capitalizes on cloud-first patterns and puts documentation in line.
- And is almost entirely scaffolded, constructed, and reliant on FOSS!
Following this pattern, so long as my notes are up to date with what I am currently working on, small changes trickle out immediately to accrete on top of my knowledge base. That base can be easily tweaked, remixed, and expressed as a webpage or publication-ready format. Pushing this site is a trivia (~2 hour long) step. Great success! Now if only it were really that easy…
A (WIP) Workflow
Finding Knowledge
- Following the standard “literature_notes” ingest process outlined in Installing Zotero.
- Take a Question/Evidence/Conclusion framing to the literature_note. Taking the concept handle (a memorable noun phrase representing a more complex idea, probably the conclusion), frame the resource as a “zettle”.
Adding Knowledge
Minimally extending content gratefully pilfered from Andyʼs working notes
Zettles should be “atomic” in that they address or concern themselves with with a single aspect of a concept handle:
- Zettle notes, in increasingly complex stages of development:
- Stubs implicitly defined through backlinks
- Bridge notes narrowly relate two adjacent terms
- Zettles: precise, narrow declarative notes
- Prefer note titles with complete phrases to sharpen claims (e.g. Human channel capacity increases with stimulus dimensionality)
- Prefer sharp titles (Prefer note titles with complete phrases to sharpen claims), and positive framings (Prefer positive note titles to promote systematic theory).
- Sometimes these are framed as questions, when evidence is too inconclusive to frame sharply (e.g. To what extent is exceptional ability heritable?, To what extent can application prompts supplant recall prompts in the mnemonic medium?)
- higher-level APIs (Concept handle note titles are like APIs)
- notes abstracting over many other notes, (e.g. Educational games are a doomed approach to creating enabling environments, Reading texts on computers is unpleasant)
- “Outline notes”, e.g. MOC
- Concept handle API’s can be loosely structured following a Diataxis framing
Who am I writing to?
[[20230923033512]] Know your audience.
Assembling a MOC or Paper
```{md}
home <- landing page
├── tutorial <- landing page
│ └── part 1 <- landing page
├── how-to guides <- landing page
│ ├── install
│ └── deploy
├── reference <- landing page
│ ├── commandline tool
│ └── available endpoints
└── explanation <- landing page
├── best practice recommendations
└── performance
Paper
├── Introduction
├── Background <- literature_notes,reference,explanation
├── Methods <- how-to guides,reference,explanation
├── Results
├── Discussion <- reference,explanation
└── Conclutions
```Undirected
- Write durable notes continuously while reading and thinking. (Evergreen note-writing as fundamental unit of knowledge work)
- Each time you add a note, add a link to it to an outline, creating one if necessary (Create speculative outlines while you write).
- Eventually, you’ll feel excited about fleshing out one of those outlines. (Let ideas and beliefs emerge organically)
- Write new notes to fill in missing pieces of the outline.
- Concatenate all the note texts together to get an initial manuscript
- Rewrite it.
Directed
- Review notes related to your topic (and a step or two beyond those—Notes should surprise you)
- Write an outline
- Attach existing notes to each point in the outline; write new notes as needed.
- Concatenate all the note texts together to get an initial manuscript
- Rewrite it.